
CF Edu 30
E Awards For Contestants
考虑枚举前两个奖分别有多少人获得,然后会发现合法第三种奖的数量形成了一段区间,我们可以预处理 RMQ 来快速得到第三种奖的最大 $c_3 - d_{-1}$ 这个东西。
然后复杂度就是 $O(n\log n + n^2)$ 了。
F Forbidden Indices
套路题。
有两种做法。首先最简单的就是建一棵 $\text{SAM}$ 然后插入 $1$ 的节点的时候把 $siz$ 设置为 $0$ ,否则为 $1$ ,然后直接算出最后的 $siz$ 枚举一遍求最大的 $len \times siz$ 即可。复杂度 $O(n)$ 。
或者可以建 $\text{SA}$ ,每次考虑一个长度的时候,用并查集把所有 $\text{height}$ 数组正好是这个长度的 $rnk[i],rnk[i-1]$ 合并起来。每次维护一下最大的并查集的 $siz$ 即可。复杂度 $O(n\log n)$ 。
CF Edu 31
D Boxes And Balls
个人觉得不错的贪心题。
考虑如果 $k=2$ ,倒过来看这个过程,会发现本质上就是个哈夫曼树合并,每次取最小的两个合并即可。
如果 $k$ 可以等于 $3$ ,可以想到能不能还是每次合并最小的三个数来做?测下第二个样例会发现,四个数的情况显然每次合并最下的三个数是错的。
会发现,如果每次合并三个可以正好合并完,那么这么合并肯定很优。否则,最后一步的时候一定会剩下正好两个数需要合并,而这两个数在这一次合并显得很亏,因为可以把之前一次合并的三个数中丢一个到这次来。这样不断调整,一定可以让最开始就合并最小的两个,使得后面都是三个三个合并的。
于是尝试是否可以直接合并完,如果不能,就先合并好前两个再做。
复杂度 $O(n\log n)$ 。
E Binary Matrix
一开始我的做法复杂了,后来去学习了一下神仙的做法,发现自己麻烦了。
由于这个空间限制甚至无法存下整个图,常规的 bfs 一类的算法肯定是不太行的了。我的做法是,每次用之前上一行做完后存下来的上一层内部的连通块来和下面的连通块连边,然后把下面的连通块合并,再把上面的连通块通过下面来合并,最后每个并查集内的上面的连通块个数减 $1$ 就是减少的连通块个数。
这么做复杂而且写挂了,拿 vector 存储图还会爆空间。
但是有很简单的做法。大概是考虑建立一个并查集表示上面的点所在的哪些连通块,下面的点所在的哪些连通块。我们先认为每个点都新成了一个连通块,然后每次拿去合并它左边和它上边的块。
实现上需要注意,每次都一定去把上面的连通块合并到下面来,这样才可以比较方便地把这一行的结果继承到下一行。
F Anti-Palindromize
又是一个可以直接费用流建图做的题。考虑对每对 $(i,n-i+1)$ ,建一个虚点,向这两个点分别连边,且长度为 $1$ ,然后从每个字符向这个虚点连长度为 $1$ 的边即可。这样就能限制每个字符只能到这两个字符之一。
但是考虑怎么把费用体现在图上,我们可以对于每一个字符分别建立 $\frac n 2$ 个虚点,然后向每个字符连边的时候连的边的费用关于这个位置的 $s$ 是否为这个字符,如果是,则有 $B_i$ 的费用。最后炮最大费用最大流即可。
点数是 $\frac {26n} 2$ 级别的。可以直接跑过去。
然后这题还有一种题解的贪心做法。我们考虑先让 $t = s$ ,然后对于每对 $s_i = s_{n-i+1}$ ,我们考虑把 $B_i,B_{n-i+1}$ 较小的那个和其他的东西交换。拿出所有最终需要交换的位置。
不难发现这个东西是一个经典的构造模型,相当于是有 $26$ 个数,分别表示每个字符有多少个需要交换的位置。然后每次可以给两个数分别减少 $1$ ,表示交换两个字符的两个位置。如果数中没有占比超过 $\frac 1 2$ 的,那么显然可以内部匹配完,最小花费可以取到下界,即所有两边相同字符的权值较小值。
如果有占比超过 $\frac 1 2$ 的,那么我们一定是把这个占比超过了一半的字符拿来和其他的尽量匹配,最后只剩这种字符。然后从剩下的位置中 $s_i,s_{n-i+1}$ 都不是这个字符的位置中选较小的 $B$ 来换即可。这样的贪心一定是对的。因为假设最后留下了两种字符,那么这两种互相匹配必然优于都去和其他本来就是好的位置匹配。
CF Edu 32
感觉 F 和 G 都挺不错,虽然 G 是以前做过的。
E Maximum Subsequence
$n \le 35$ ,可以想到折半搜索。我们折成两半,对左边的每种 $2^{17}$ 的状态,存一下 $a$ 的和。然后再枚举右边的所有状态,如果右边的 $a$ 的和是 $s$ ,那么只需要再左边查 $< P-s$ 的最大的数即可。
如果左右找到的数加起来大于 $P$ 了,显然不如把右边的数都丢弃掉直接拿左边的好。
复杂度 $2^{\frac n 2} n$ 。
F Connecting Vertices
感觉不错的区间 $dp$ ,想一想还是可以做。
做法大概是直接设 $dp[l][r]$ 表示区间之内的所有点都连成了一个生成树的方案数量。
考虑如何进行转移。一种直接的转移的方式是 $dp[l][k] \times dp[k + 1][r]$ ,然后从 $[l,k]$ 向 $[k+1,r]$ 连一条边。这样直接转移显得非常困难,因为无法确定连边的方案数量。
所以我们观察一下最后得到的生成树的图形,
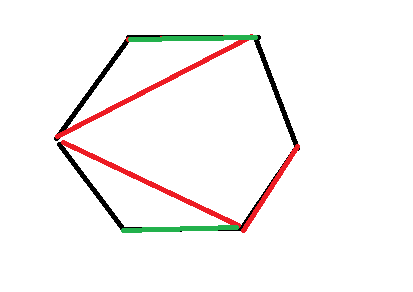
会是几个最里层的连起来的轮廓(红色部分)和一些轮廓之外的边(绿色部分)。
于是有了另一个想法,假设当前需要求的区间是 $[i,j]$ ,我们钦定第一个外轮廓的边是 $[i,k]$ ,然后剩下的 $[k,j]$ 就任意求一个生成树。因为已经钦定了 $[i,k]$ 是一个轮廓,必然不存在从这个区间内到区间外的边了,也就杜绝了这两个区间相互影响。
然后再设 $pd[i][j]$ 表示钦定 $i \to j$ 有一条边(作为轮廓边)里面的生成树个数。
转移就是
复杂度 $O(n^3)$ 。
G Xor-MST
经典题。
我们把所有数丢到 trie 中,然后在 trie 上来做分治。
考虑 trie 某个子树之内的所有点,显然它们应当在子树内先连成一个生成树,再去向外连边。因为如果里面有两个点都向外连的有边,不如把其中一个边变成子树内的,子树内的边的大小是严格小于子树外的(因为最高为 $1$ 和 $0$ 的存在)。
然后现在我们假设对当前点 $u$ 的两个儿子的子树都已经连成了一个生成树,我们显然需要找左右儿子中异或起来最小的两个数。这个大概有两种想法,第一种是枚举较小的那一边的所有数,再在较大的那一边查询,这样做复杂度类似于启发式合并,合并的过程是 $O(siz\log n)$ 的,所以复杂度是 $O(n\log^2 n)$ 的。
但是又一种比较好些的做法,复杂度是一样的。我们考虑两个点 $u,v$ ,它们深度相同且我们要找子树内异或起来最大的值。我们考虑如果它们同时有 $0$ 边,就同时向 $0$ 走,如果同时有 $1$ ,又同时向 $1$ 走。如果都不存在,就尝试往两个方向分别走。这样每次询问的时候走的次数一定是较小的 $siz \times \log n$ 的,因为一边走到底部,另一边必须对应走到一个底部,必须是两两对应,所以最后走到底部的次数一定是较小的 $siz$ 次。
CF Edu 33
E Counting Arrays
先不考虑正负。考虑 $x$ 分解质因数,假设是 $\prod p_i^{w_i}$ 。我们对每个质因子分别考虑。对于一个 $w_i$ ,不难发现相当于是可以把这个 $w_i$ 给分配到 $y$ 个位置上,每个位置上的值 $\ge 0$ ,也就是一个方程 $x_1 + x_2 + \cdots x_y = w_i$ 的解的个数种方法。这个东西可以直接插板法。
考虑正负号,相当于是选择偶数个位置作为负数。也就是 $\sum_{2|i} \binom n i$ 这个东西,当 $n \ge 1$ 它等于 $2^{n-1}$ 。所以式子就是
直接分解质因数即可。复杂度 $O(T\sqrt x)$ ,可以跑过去。
F Subtree Minimum Query
考虑这个限制,写出来其实就是
由于求最小值,是没有可减性的。所以我们应当用主席树维护第二维,也就是按深度从小到大加入点,然后询问就是主席树上的区间最小值。